在阅读理解这件事上,AI已甩人类几条街?
时间:2018-02-24 15:16:48 来源:huxiu.com
[导读]2017年,由李飞飞团队创建的鼎鼎有名的ImageNet视觉识别挑战赛走向谢幕。回顾往昔,ImageNet在2012年引爆了深度卷积神经网络,并继而在3年后推动谷歌、微软、百度等公司在图像识别领域超过人类。在图像识别领域,ImageNet可谓功不可没。而如今在另一个数据集上,或许也正上演同样的故事。

2017年,由李飞飞团队创建的鼎鼎有名的ImageNet视觉识别挑战赛走向谢幕。回顾往昔,ImageNet在2012年引爆了深度卷积神经网络,并继而在3年后推动谷歌、微软、百度等公司在图像识别领域超过人类。在图像识别领域,ImageNet可谓功不可没。
而如今在另一个数据集上,或许也正上演同样的故事。在2018年伊始,阿里巴巴和微软亚洲研究院相继刷新了斯坦福大学发起的SQuAD(Stanford Question Answering Dataset)文本理解挑战赛成绩,机器阅读理解评分超过人类!这意味着机器阅读理解的能力已经开始在“指标”上超越人类,又是否能够引领自然语言处理(NLP)领域的下一场革命?
近日,百度自然语言处理团队也拿下了微软MS MARCO(Microsoft MAchine Reading COmprehension)机器阅读理解测试首名。
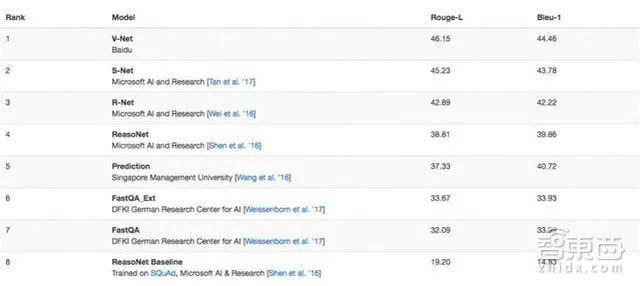
百度在微软MARCO中获第一名
“自然语言处理是人工智能桂冠上的明珠”,这句话反应了NLP发展之艰巨。而这些公司们陆续在NLP比赛上取得胜利,是否意味着机器阅读理解真的能够超过人类?我们采访了近10位NLP领域的资深人士,他们中既有NLP类创业公司的CEO/技术高管(如康夫子张超、思必驰葛付江、猎户星空闵可锐),又有大公司的技术负责人(如搜狗刘明荣、科大讯飞王士进)等。
通过沟通我们认识到,机器在阅读理解的评分上超过人类,也许是NLP发展历程上的一次重大突破,意味着机器在“指标”上对人类的胜利,机器也确实可以在限定场景下有超过人类的表现。但这终究是一场“指标性”胜利,想要做到能理解会思考,机器还有“万里长征路”要走 。
一、公开数据集掀起算法竞赛
在谈NLP发展现状之前,我们先看一下斯坦福的SQuAD和微软MS MARCO两个机器阅读理解数据集。
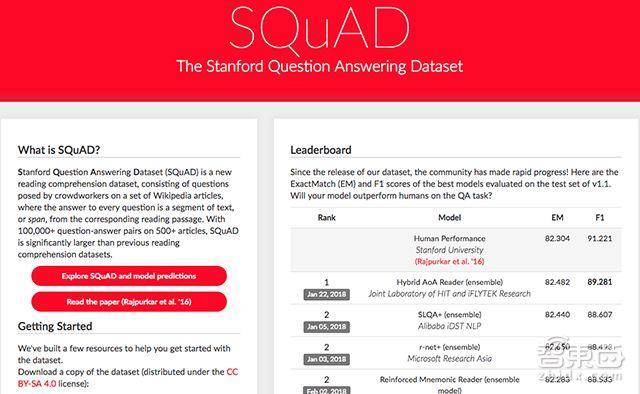
SQuAD是斯坦福大学于2016年推出的阅读理解数据集,也是行业内公认的机器阅读理解标准水平测试,该数据集包含来自维基百科的536篇文章及共计十万多个问题。在阅读数据集内的文章后,机器需要回答若干与文章内容相关的问题,通过与标准答案对比来获取得分。这个数据集有两个评判标准:EM(Exact Match)代表完全匹配,即机器给出的答案和标准答案一样才算正确;F1代表模型的整体性能。
在EM值上,人类在该项得分为82.304,而阿里和微软在前不久的得分中稍高于人类得分,分别为82.440和82.650,这也是为何阿里和微软称机器阅读理解得分超过人类。目前整体排名第一的是科大讯飞与哈工大联合实验室,EM得分为82.482,F1得分89.281。
微软MARCO也应用在机器阅读理解领域,是由10万个问答和20万篇不重复的文档组成的数据集。相比SQuAD,其最大不同在于数据集中的问题来自微软自家必应搜索引擎。根据用户在必应中输入的真实问题模拟搜索引擎中的真实应用场景,可以看出微软希望借此数据集提升用户获取信息方面的能力。
百度称,MARCO的挑战难度更大,它需要测试者提交的模型具备理解复杂文档、回答复杂问题的能力,百度之所以选择该数据平台,是更致力通过技术应用解决搜索中的实际问题。
可以看出,在机器阅读理解比赛中,百度、阿里、科大讯飞、微软等公司取得较为优异的排名,也体现出我国对于NLP方面的研究在全球也处于前列的位置。这些阅读理解的数据集也使训练大规模复杂算法成为可能。各大公司通过数据集优化算法,从而解决自然语言实际问题,进一步推动自然语言处理的发展。
二、一场限定边界场景的“指标性”胜利
针对阿里、微软、百度等在机器阅读理解方面的表现,我们采访的NLP领域资深人士均表示,机器阅读理解取得的成绩确实是一个突破性的进展,其可能是继机器翻译之后又一个取得重要进展的NLP领域;但机器阅读理解仍然是一种限定边界的任务,远远达不到真正的归纳和推理 ,因此对于人类的胜利更应该说是“指标”上的胜利。
搜狗搜索事业部NLP技术负责人刘明荣谈到,在斯坦福SQuAD比赛中,阿里和微软评分超过人类这一成绩确实是NLP领域一个重要的进步,表明在特定任务上机器已经取得了和人类相当的水平,在特定场景下已经做到了接近实用水平。
认同这一观点的还有思必驰NLP资深工程师葛付江,他指出一方面机器阅读理解属于篇章理解,需要从篇章中找到相关信息并回答问题,相对于词语和句子理解这是一项比较高级的NLP任务;另一方面机器阅读理解是一种边界限定的场景式机器理解,问题的前提条件和场景边界都比较清楚,所以机器阅读理解超过人类是以“设定文章集合、有限问题”为前提条件的。
相比前几年,阿里和微软在机器阅读理解中评分超过人类,确实体现了NLP技术的快速进步和发展。但同时,葛付江也表示,机器阅读理解离真正的人类水平还有很长的路要走。

关于机器阅读理解超过人类的说法并不正确 ,猎户星空首席科学家闵可锐向智东西解释到,特定任务数据集可以说是对特定任务的一个代理(对世界的抽象),我们的测试是基于这个代理任务,所以代理本身的有效性很关键。比如语音识别中采用播音员,在无噪声情况下的数据算法能够达到很高的准确率,但未必代表语音识别超过人类,因为这个代理任务过于简单。
同样的SQuAD的数据设计将文本限定在维基上,并且只有500多篇内容,这也相当于作了简化。灵隆科技首席科学家汤跃忠博士也指出这类比赛都是限定条件的,其评价指标也有一定的片面性。
而同样是阅读理解任务,智东西了解到,百度也公布过一个不论在难度还是在规模上更大的DuReader数据集,目前最好的模型与人的准确率相比也有近20个点的差距。因此尽管通过神经网络端到端的架构机器阅读理解有突破性进展,但远谈不上超过人类。
康夫子创始人兼CEO张超补充到,这只说明基于端到端的深度学习框架可以在“阅读理解”任务上做出不错的成绩,本身还是深度学习在NLP应用领域的探索。但大多数问题仍没有到达需要“推理”的级别,对于机器阅读理解“能理解会思考”的终极目标来说,现在还是只万里长征的开始。
三、NLP发展现状:初落行业,限定场景大有可为
微软全球执行副总裁沈向洋曾说过,人工智能的突破在于自然语言理解,“懂语言者得天下”。自然语言处理也被称为“人工智能桂冠上的明珠”,足以体现该领域之难之重要。
而经过近年深度学习的发展,目前NLP开始落地行业,可谓“初出茅庐”,通过限定边界场景,已经开始进入家居、车载、金融、医疗、教育等众多领域 ,未来发展前景不可限量。
科大讯飞北京研究院院长、AI研究院副院长王士进谈到,随着深度学习技术的发展,NLP在人机问答、神经机器翻译、阅读理解、用户画像和精准推荐等领域取得了很大的技术突破,并且在金融、教育、法律、医疗等领域逐步广泛应用。
具体来看,搜狗刘明荣表示NLP经过几十年的发展,目前在词法、句法等浅层语言分析任务上已经达到相当高的实用水平。在一些具体的NLP任务上,比如语音方面的语音识别和合成,文本方面的文本分类、情感分析、文本摘要、机器翻译等,也基本达到了实用阶段。
而思必驰葛付江从知识图谱的维度谈到,伴随着知识图谱技术的发展,NLP在垂直场景上的产品化落地也在加快,诸如智能家居、车载、机器人、企业对话服务等场景。当今,NLP进步的动力在于真实的应用场景正在不断出现,与此同时也将带来更多的场景需求,创造更多数据,进而推动NLP的进一步发展。

而以机器阅读理解来说,机器能够超过人类的在于“指标”,但真正在通用领域超过人类,在较长时期内还是不现实的。
“以机器阅读理解任务来说,机器应该很快会从指标上超过人类的现有水平,但真正的阅读理解过程需要深层的推理和归纳,这恰恰是目前机器所欠缺的,还需要通过底层算法的突破才有可能实现机器在NLP领域的真正突破。 ”王士进谈到。
而人做阅读理解和机器做阅读理解是两个层面的事。康夫子CEO张超表示,对于机器来讲,阅读理解任务可抽象为“把文章和问题作为输出,来判断哪个答案最为可能”,这时题型或者重点一旦发生变化,整个机器的效果可能直线下降。而人的阅读理解则是读完后的融会贯通,真正做到理解、运用、推理甚至想象。
但刘明荣也指出,尽管通用领域机器还不能够超越人类,但在特定行业下,基于对特定行业资料的理解所产生的机器人。如客服机器人,至少可以达到和人类的理解水平相当,并且在整体效率上远远超过人类。

可以看出,目前NLP的商业化以及落地行业才刚刚开始,如果将NLP放到一条发展线上,目前还处于中初期,限定边界下才大有可为。由于其涉及到大量认知层面的理解,仍然是一个十分有挑战的问题,在知识表达、常识表达和知识推理上还有很长的路要走。
四、NLP发展的关键在于垂直领域快速落地
近年来随着智能音箱在全球市场的盛行,语音交互持续火热,机器翻译、机器同声传译等快速发展,对NLP的进步产生巨大需求。面对当下NLP发展现状,业内资深人士也从数据、底层算法、知识图谱、应用等维度给出进一步发展的办法。

思必驰葛付江认为,大规模的数据集或数据平台、积极开放的研究氛围对于NLP技术的发展至关重要。而垂直领域产品化落地将是推动NLP技术进步最重要的动力,它会带来更多的流动数据、研究投入和社会资源,推动NLP进一步的发展。
结合实际应用需求,搜狗刘明荣认为产学研相结合是推动NLP发展的一大动力。结合实际问题,建立大规模评测数据和规范的评测方法,让学术界和工业界共同参与,才能够更好的解决目前存在的难题。
猎户星空闵可锐表达了其对知识和语义表达的兴趣,通过近两年有较大发展的神经机器翻译技术来看,他认为这一定程度上证明了语义向量表达的可能性,猎户星空也在探索通过无标注数据或可大量获取的弱标注数据来进行精确的语义建模。
此外,康夫子CEO张超从自身医疗机器人的维度谈到,下一步推动NLP发展可能再知识图谱层面,通过知识图谱构建机器对任务的认知能力,再加以语义、交互等处理工具,通过应用才能更好推动一个行业的发展。
而强调通过知识图谱来推动NLP发展的不止张超,还有阿里AI Labs北京研发中心负责人聂再清博士。
他希望建立一个知识图谱的生态平台,让大量的开发人员在上面去建立知识图谱,使用积累的知识图谱,不断扩大知识图谱在常识性和专业性方面的积累,即共建知识图谱,产生1+1>2的效果。
结语:引爆人工智能下一场革命?
不得不说,机器阅读理解在“指标”上已超过人类,未来将会在“指标”上全面超过人类,机器阅读理解又能否向图像识别一样,引领人工智能的下一场革命?随着NLP方面的突破,智能助手、智能客服、机器翻译等都将大幅提升,惠及金融、教育、家居、车载等众多行业!
但归根结底,机器不能像人一样做到真正的理解、融会贯通、推理,其只是一场限定边界场景的“指标性”胜利。机器想要做到能理解会思考,现在还只是万里长征的开始。
而作为人工智能桂冠上的明珠,NLP技术的重要性和挑战性不言而喻。在当下将NLP在垂直领域快速产品化落地、知识图谱的构建以及底层算法的突破都将进一步推动认知智能的发展。

声明:i天津视窗登载此文出于传送更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供网友参考,如有侵权,请与本站客服联系。信息纠错: QQ:1296956562 邮箱:1296956562@qq.com





